Set
주요 특징
Set(세트/셋)은 유일한 요소들의 컬렉션이다.
- 유일성 : 중복된 요소를 허용하지 않는다.
- 추가시 이미 존재하는 요소시 무시
- 순서의 미보장
- 빠른 검색
중복을 허용하지 않고, 요소의 유무만 중요한 경우 사용됨.
한계
Set는 구조는 단순하나 데이터 추가, 검색 모두 O(n)의 시간 복잡도로 성능이 좋지 않고 데이터가 많을 수록 더욱 더 효율이 떨어진다. 검색의 경우 ArrayList 와 LinkedList 의 성능과 비슷하지만, 데이터 추가시 중복을 체크하기 위해 전체 데이터를 순회( O(n) )하는 단점이 있다.
⇒ 이를 극복하기 위해 Hash(해시) 알고리즘을 도입한다.
HashSet
앞서 말한 Set의 단점을 Hash 알고리즘의 도입으로 보완한 자료구조
남겨진 문제
- 배열의 인덱스 == 데이터 매칭은 숫자만 이용이 가능하다.
HashCode
- 컴퓨터는 문자를 문자로 인식하는 것이 아니라 고유의 숫자를 할당해서 인식한다. (ASCII 코드 참고)
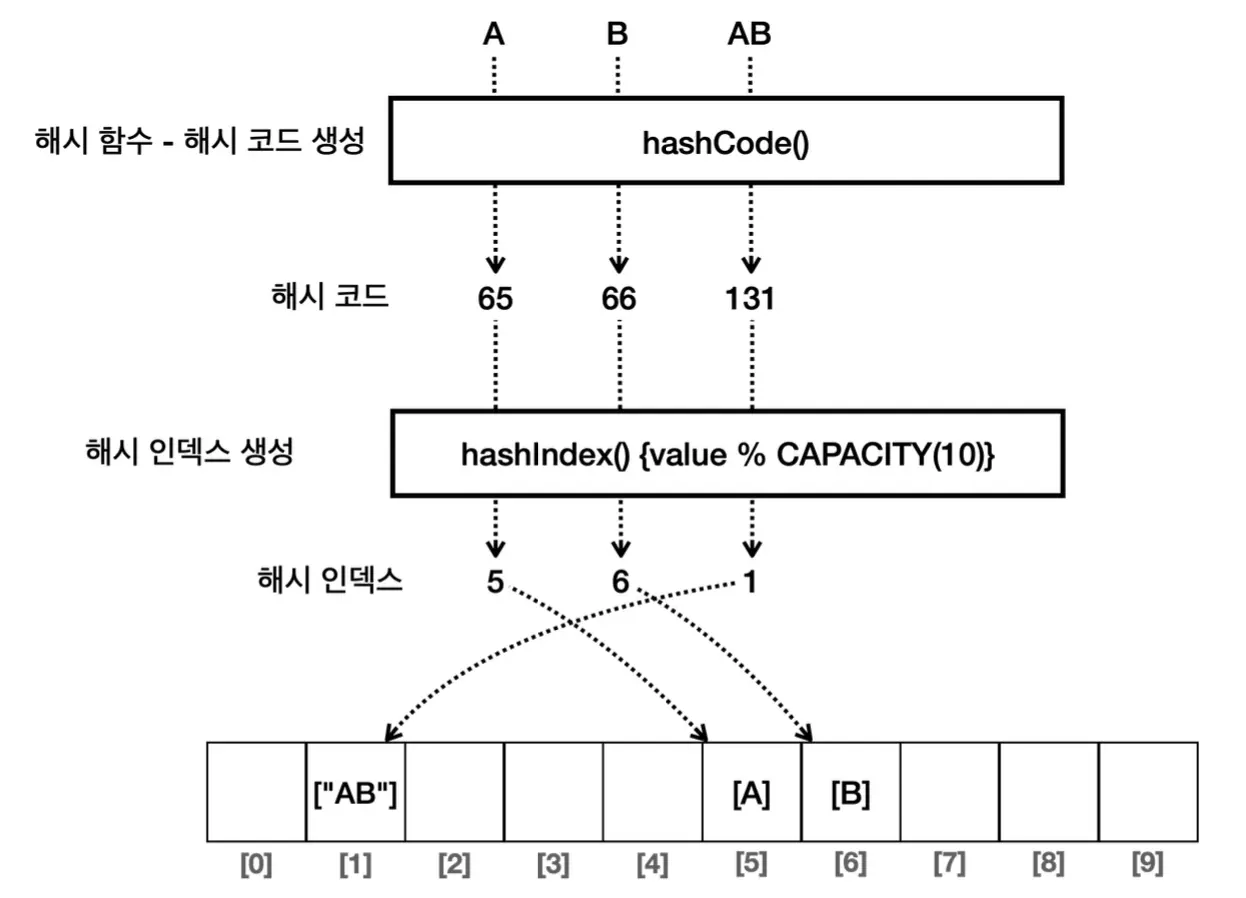
Java의 경우 Object 단에서 이미 hashCode() 메서드가 정의돼 있다. 즉, hashCode() 메서드의 재정의로 Java 세상의 모든 객체에서 hashCode를 뽑아낼 수 있다.
equals와 hashCode의 중요성
반드시 구현해야 하는 이유
두 메서드 모두 동등성을 비교해야만 한다. 재정의 하지 않으면 Object의 hashCode가 실행됨
- 해시 인덱스가 같아도 저장된 실 데이터의 값이 다를 수 있다. ⇒ 충돌이 일어난 경우 equals로 비교해 검증해야함
- 일관된 hashCode를 얻어내야함. 이 때의 비교는 논리적 동등성이여야만 한다.
예시 객체의 id값으로 동등성을 비교해야 한다. → 재정의 하지 않고 Object의 hashCode 사용 시 Java 메모리단에서의 참조값을 활용해 hashCode와 equals를 비교하기 때문에 의도한 바와 다르게 동작.
최종 Set
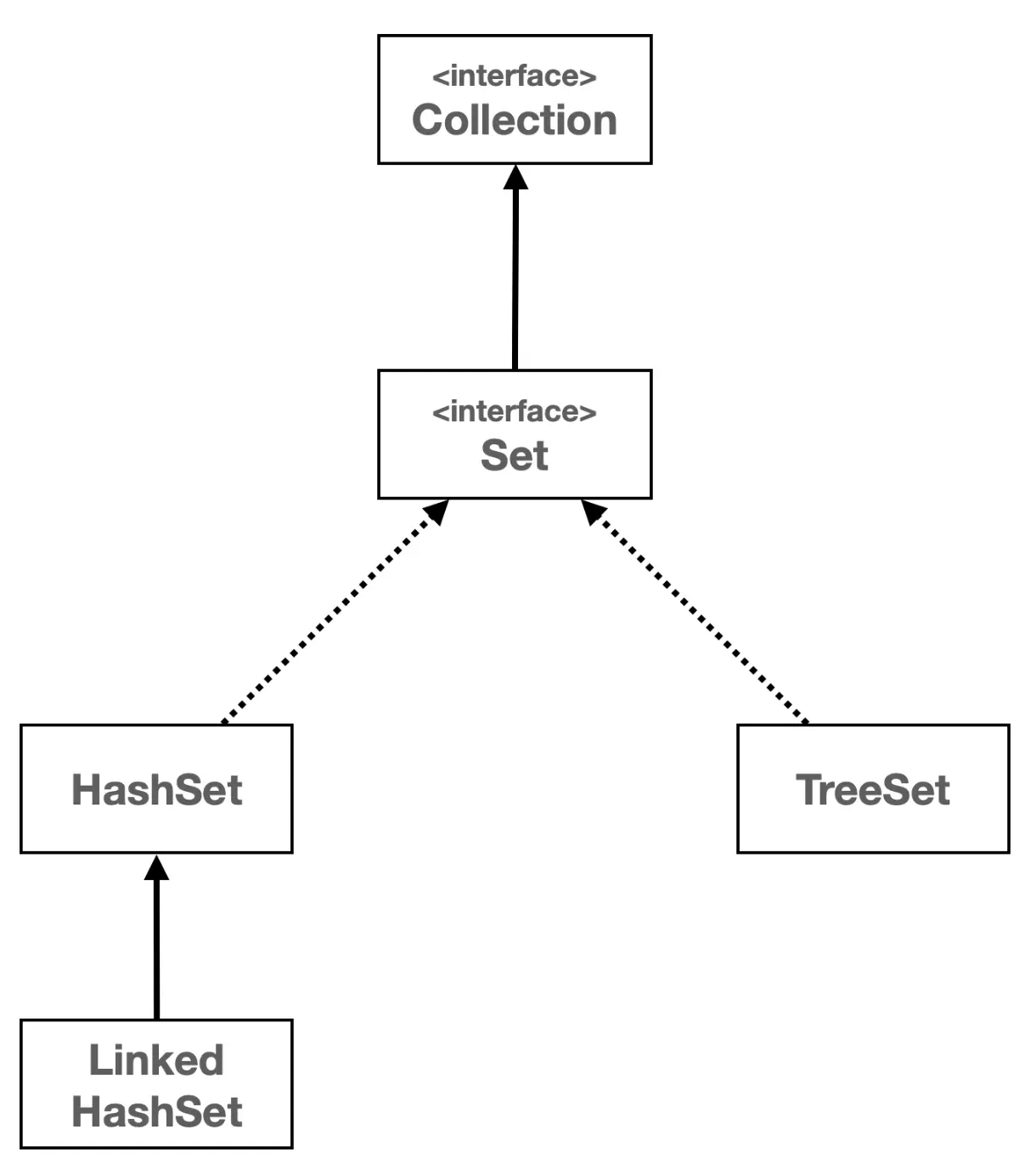
- HashSet
- 구현 : 해시 자료 구조를 사용해 요소 저장
- 순서 : 보장되지 않음
- 시간 복잡도 : (추가, 삭제, 검색) 평균 O(1)
- LinkedHashSet
- 구현 : HashSet에 연결 리스트를 추가해서 요소들의 순서를 유지
- 순서 : 추가된 순서대로 유지됨
- 시간 복잡도 : 평균 O(1)
- TreeSet
- 구현 : 이진 탐색 트리를 개선한 레드-블랙 사용
- 순서 : 정렬된 순서대로 저장, 순서의 기준은 Comparator로 변경
- 시간 복잡도 : O(log n)
최적화
통계적으로 데이터의 수가 배열 크기의 75%를 넘어가면 인덱스 충돌이 자주 일어난다. (성능이 떨어짐)
Java에서는 데이터의 양이 배열 크기의 75%를 넘어가면 배열의 크기를 2배로 늘린다.